16-08 리샘플링 (resample)
DataFrame.resample(rule, axis=0, closed=None, label=None, convention='start', kind=None, loffset=None, base=None, on=None, level=None, origin='start_day', offset=None)
개요
resample는 Datetime Index를 원하는 주기로 나누어주는 메서드 입니다.
이러한 방식을 리샘플링(resample)이라고 합니다.
asfreq와 유사 하지만 더 많은 기능과 설정을 할 수 있으며, 리샘플링으로 생성된 행의 값 또한 여러 방식으로 생성할 수 있습니다.
사용법
기본 사용법
※ 설명으로는 이해하기 힘든 내용입니다. 자세한 내용은 아래 예시를 참고 바랍니다.
df.resample(rule, axis=0, closed=None, label=None, convention='start', kind=None, loffset=None, base=None, on=None, level=None, origin='start_day', offset=None)
rule : 리샘플링 할 기준 입니다. 단위로는 Y, M, D, H, T(min), S ... 등을 조합하여 사용할 수 있습니다.
axis : 리샘플링할 축 입니다.
closed : {left / right} 간격의 시작과 끝중 어느부분을 닫을지 입니다. 기본적으로 왼쪽(시작) 입니다.
간단히 예를들면 1분간격 인터벌로 01:00의 값이 1이라고하면 left는 시작부분을 닫아 01:00≤ x<02:00인 시간의 값을 1으로,
right는 끝 부분을 닫아 00:00<x ≤01:00인 시간의 값을 10이라고 판단하는 것입니다.
label : {left / right} 리샘플링될 시간을 포함하는 간격의 어떤 가장자리를 레이블로 정할지 입니다. 기본적으로 왼쪽 입니다.
convection : {start, end, s, e} PeriodIndex의 경우에만 규칙의 시작 또는 끝을 사용할지 여부를 제어합니다.
kind : {timestamp / period} 결과 인덱스를 DateTimeIndex로 변환하려면 'timestamp'를 전달하고 PeriodIndex로 변환하려면 'period'를 전달합니다. loffset : 리샘플링된 시간 레이블을 조정하는 인수로 현재는 사용하지 않습니다. (offset 인수로 대체)
base : 리샘플링한 데이터의 간격의 원점을 지정하는 인수로, 현재 사용하지 않습니다.(origin 인수로 대체)
on : 인덱스가 아닌 열 기준으로 리샘플링을 시도할 경우, 해당 열의 이름을 지정하는 인수 입니다.
level : 멀티인덱스(Multi Index)의 경우 리샘플링할 인덱스의 레벨을 지정하는 인수 입니다.
origin : {epoch, start, start_day, end, end_day / Timestamp} 리샘플링할 경우 데이터 간격의 원점을 지정합니다.
epoch : 1970-01-01을 기준으로 간격을 설정합니다.
start : 인덱스의 첫 번째 값을 기준으로 간격을 설정합니다.
start_day : 인덱스의 첫 번째 값이 포함되는 날의 자정을 기준으로 간격을 설정합니다.
end : 인덱스의 마지막 값을 기준으로 간격을 설정합니다.
end_day : 인덱스의 마지막 값이 포함되는 나르이 자정을 기준으로 간격을 설정합니다.
Timestamp : 지정한 시간(Timestamp)를 기준으로 간격을 설정합니다.
offset : origin의 값에 시간 오프셋을 더해줍니다.
예시
먼저 기본적인 사용법 예시를위하여 10x1짜리 데이터를 만들어보겠습니다.
pd.date_range를 이용해 기준시간에 대해 일정 간격을 가진 datetime index를 생성하겠습니다.
idx = pd.date_range('2021-12-30',periods=10,freq='min')
# 2021-12-30일기준으로 1분간격의 10개의 행 생성
df = pd.DataFrame(index=idx, data=[0,1,2,3,4,5,6,7,8,9],columns=['col'])
print(df)
>>
col
2021-12-30 00:00:00 0
2021-12-30 00:01:00 1
2021-12-30 00:02:00 2
2021-12-30 00:03:00 3
2021-12-30 00:04:00 4
2021-12-30 00:05:00 5
2021-12-30 00:06:00 6
2021-12-30 00:07:00 7
2021-12-30 00:08:00 8
2021-12-30 00:09:00 9
기본적인 사용법
resample 메서드는 단독으로 사용하면 아래와 같이 DatetimeIndexResampler를 생성합니다.
print(df.resample(rule='3T'))
>>
DatetimeIndexResampler [freq=<3 * Minutes>, axis=0, closed=left, label=left, convention=start, origin=start_day]
우리가 원하는 리샘플링된 데이터를 출력하고자 하면, 다른 메서드를 뒤에 붙여서, 리샘플링된 데이터의 열의 값을 지정해주어야합니다.
1분간격으로 1~10까지의 값을 가지는 데이터를 3분(3T or 3min) 간격으로 리샘플링하면서, 값은 합치도록 해보겠습니다.
print(df.resample(rule='3T').sum()) # 뒤에 .sum()을 붙여주어서 합쳐질 열의 값을 더해줍니다.
>>
col
2021-12-30 00:00:00 3 # 0분, 1분, 2분이 리샘플링되어 0+1+2
2021-12-30 00:03:00 12 # 3분, 4분, 5분이 리샘플링되어 3+4+5
2021-12-30 00:06:00 21 # ...
2021-12-30 00:09:00 9 # ...
sum() 뿐만아니라 prod(), mean()등 객체간 연산 에 이용되는 모든 메서드가 가능하며,
asfreq같은 메서드등도 지원합니다.
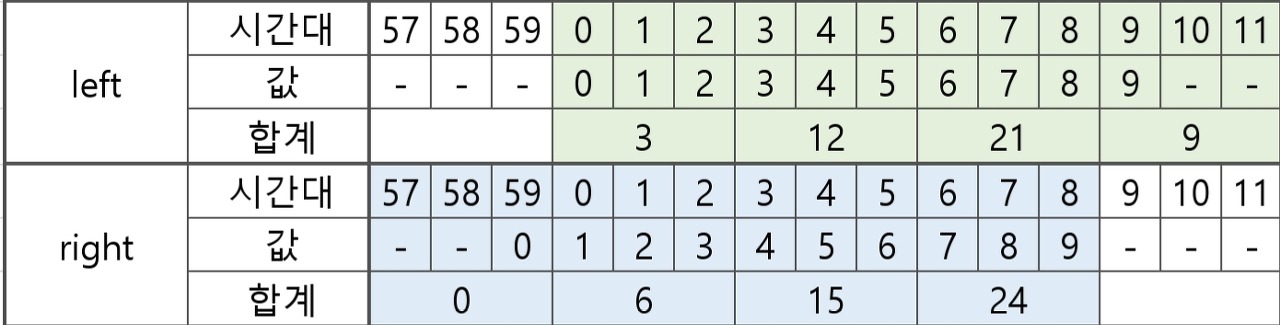
closed인수의 사용
closed인수는 bin(시간 간격)을 닫는 위치를 지정하는 인수로 기본적으로 left값을 가집니다.
1분 간격 인터벌인 df값 중 2021-12-30 00:03:00 3의 예시를 들면, left인 경우는 03:00≤ x <04:00인 시간간격에 3이 부여되는 것이고,
right인 경우는 02:00< x ≤03:00 인 시간 간격에 3이 부여되는 것입니다.
아래 예시와 그림을 보면 이해가 쉽습니다.
# closed='left'인 경우
print(df.resample(rule='3T',closed='left').sum())
>>
col
2021-12-30 00:00:00 3
2021-12-30 00:03:00 12
2021-12-30 00:06:00 21
2021-12-30 00:09:00 9
# closed='right'인 경우
print(df.resample(rule='3T',closed='right').sum())
>>
col
2021-12-29 23:57:00 0
2021-12-30 00:00:00 6
2021-12-30 00:03:00 15
2021-12-30 00:06:00 24
left인 경우 00:00≤ x <03:00 인 시간대에 0,1,2가 들어가기 때문에 00:00부터 리샘플링하여 0+1+2=3 이 출력됩니다. right인 경우 0은 23:59:00< x ≤ 00:00:00인 시간대에 들어가므로 3분 단위 리샘플링이 23:57:00< x ≤ 00:00:00 으로 0이 출력됩니다.
아래 이미지를 보면 보다 직관적으로 이해할 수 있습니다.
label 인수의 사용
label인수는 closed인수보다는 개념이 간단합니다. 단순히 리샘플링된 인덱스의 간격을 대표할 값을
간격의 시작값으로할지 끝 값으로할지를 지정하는 것입니다. 기본값은 left로 인터벌(간격)의 시작을 기준으로합니다.
# label = 'left'인 경우
print(df.resample(rule='3T',label='left').sum())
>>
col
2021-12-30 00:00:00 3 # 00:00~03:00의 간격에서 시작값인 00:00을 기준으로 지정
2021-12-30 00:03:00 12
2021-12-30 00:06:00 21
2021-12-30 00:09:00 9
# label = 'right'인 경우
print(df.resample(rule='3T',label='right').sum())
>>
col
2021-12-30 00:03:00 3 # 00:00~03:00의 간격에서 끝값인 03:00을 기준으로 지정
2021-12-30 00:06:00 12
2021-12-30 00:09:00 21
2021-12-30 00:12:00 9
kind 인수의 사용
kind 인수는 리샘플링된 인덱스의 dtype을 datetime으로 할지 peroid로할지 정할 수 있습니다.
index의 dtype정보는 10-10 인덱스 (index) 항목에서 확인할 수 있습니다.
kind='timestamp'인 경우 DatetimeIndex가 됩니다.
print(df.resample(rule='3T',kind='timestamp').sum().index)
# index메서드를 통해 인덱스 정보 확인 가능
>>
DatetimeIndex(['2021-12-30 00:00:00', '2021-12-30 00:03:00',
'2021-12-30 00:06:00', '2021-12-30 00:09:00'],
dtype='datetime64[ns]', freq='3T')
# 분류가 DatetimeIndex 이며 dtype='datetime`으로 설정됨.
kind='period'인 경우 PeriodIndex가 됩니다.
print(df.resample(rule='3T',kind='period').sum().index)
>>
PeriodIndex(['2021-12-30 00:00', '2021-12-30 00:03', '2021-12-30 00:06',
'2021-12-30 00:09'],
dtype='period[3T]')
# 분류가 PeriodIndex 이며 dtype='period`로 설정됨.
on 인수의 사용
먼저 on인수의 사용을 위해 열의 값이 timestamp형태인 데이터를 만들어보겠습니다.
idx = pd.date_range('2021-12-30',periods=2,freq='5min')
df = pd.DataFrame(index=idx, data=[1,6],columns=['col'])
# 5분간격의 2개 열을 가진 데이터 생성
df2 = df.reset_index(drop=False)
# reset_index를 통해 기존인덱스를 열로 변경, 새 인덱스는 0,1,2, ... , n으로 변경.
print(df2)
>>
index col
0 2021-12-30 00:00:00 1
1 2021-12-30 00:05:00 6
# 기존 index가 'index'라는 이름의 열로 바뀜
※ reset_index에 대한 자세한 내용은 13-09 인덱스 리셋 (reset_index)을 참고 바랍니다.
on=index를 입력하여 index라는이름을 가진 열을 기준으로 리샘플링을 진행해보겠습니다.
print(df2.resample(rule='min',on='index').sum())
# 5분간격으로 2개의 값을가지는 `index`열을 1분(min) 간격으로 리샘플링.
>>
col
index
2021-12-30 00:00:00 1 # index라는 이름의 열 기준으로 리샘플링이 진행되고
2021-12-30 00:01:00 0 # 해당 열이 index로 변경됨.
2021-12-30 00:02:00 0
2021-12-30 00:03:00 0
2021-12-30 00:04:00 0
2021-12-30 00:05:00 6
origin 인수의 사용
먼저, origin인수와 offset인수를 사용하기 위해 3분간격의 9행짜리 Timeindex 데이터를 만들어보겠습니다.
idx = pd.date_range('2021-12-31',periods=9,freq='3min')
df = pd.DataFrame(index=idx, data=[1,2,3,4,5,6,7,8,9],columns=['col'])
print(df)
>>
col
2021-12-31 00:00:00 1
2021-12-31 00:03:00 2
2021-12-31 00:06:00 3
2021-12-31 00:09:00 4
2021-12-31 00:12:00 5
2021-12-31 00:15:00 6
2021-12-31 00:18:00 7
2021-12-31 00:21:00 8
2021-12-31 00:24:00 9
이것을 7min 간격으로 리샘플링을 진행해보겠습니다.
print(df.resample(rule='7min').sum())
>>
col
2021-12-31 00:00:00 6
2021-12-31 00:07:00 9
2021-12-31 00:14:00 13
2021-12-31 00:21:00 17
origin인수의 기본값은 start_day로 처음값이 포함된 날짜의 시작시간인 자정(00:00:00)을 기준으로 7분 간격으로 리샘플링을 진행합니다.
print(df.resample(rule='7min',origin='start_day').sum())
>>
col
2021-12-31 00:00:00 6
2021-12-31 00:07:00 9
2021-12-31 00:14:00 13
2021-12-31 00:21:00 17
origin='start'인 경우 처음 값을 기준으로 7분 간격으로 리샘플링을 진행하게됩니다.
여기서는 시작시간이 00:00:00이므로 start_day인 경우와 동일합니다.
print(df.resample(rule='7min',origin='start').sum())
>>
col
2021-12-31 00:00:00 6
2021-12-31 00:07:00 9
2021-12-31 00:14:00 13
2021-12-31 00:21:00 17
origin='epoch'인 경우 1970-01-01을 기준으로 7분 간격의 리샘플링을 하게 됩니다.
print(df.resample(rule='7min',origin='epoch').sum())
>>
col
2021-12-30 23:55:00 1
2021-12-31 00:02:00 5
2021-12-31 00:09:00 15
2021-12-31 00:16:00 15
2021-12-31 00:23:00 9
origin='end'인 경우 마지막 값을 기준으로 7분간격으로 리샘플링을 진행하게 됩니다.
print(df.resample(rule='7min',origin='end').sum())
>>
col
2021-12-31 00:03:00 3
2021-12-31 00:10:00 7
2021-12-31 00:17:00 11
2021-12-31 00:24:00 24
origin='end_day'인 경우 마지막값이 포함된 날의 끝 시간인 자정(00:00:00)을 기준으로 7분 간격의 리샘플링을 진행 합니다.
print(df.resample(rule='7min',origin='end_day').sum())
>>
col
2021-12-31 00:05:00 3
2021-12-31 00:12:00 12
2021-12-31 00:19:00 13
2021-12-31 00:26:00 17
origin값에 특정 날짜를 입력할 경우 그 날짜(시간)을 기준으로 리샘플링이 진행됩니다.
print(df.resample(rule='7min',origin='2021-12-30').sum())
>>
col
2021-12-30 23:55:00 1
2021-12-31 00:02:00 5
2021-12-31 00:09:00 15
2021-12-31 00:16:00 15
2021-12-31 00:23:00 9
offset인수의 사용
먼저 offset인수를 사용하지 않은 경우를 보겠습니다.
print(df.resample(rule='7min').sum())
>>
col
2021-12-31 00:00:00 6
2021-12-31 00:07:00 9
2021-12-31 00:14:00 13
2021-12-31 00:21:00 17
offset인수는 origin에 대해서 시간을 더하는 인수입니다.
만약 offset='4min'을 지정해준다면, 기본값인 origin='start_day'인 첫 값이 포함된 날의 자정(00:00:00)을 기준으로
4분을 더해준 값인 00:04:00을 기준으로 리샘플링이 진행되게 되는 것입니다.
즉, origin = '2021-12-31 00:04:00'으로 입력한 경우와 완벽히 같습니다.
print(df.resample(rule='7min',offset='4min').sum())
>>
col
2021-12-30 23:57:00 3 #00:04:00 기준으로 리샘플링이 진행됐기 때문에, 00:04:00에서 7min을 뺀 23:57부터 리샘플링이 진행됨.
2021-12-31 00:04:00 7
2021-12-31 00:11:00 11
2021-12-31 00:18:00 24
※ resample메서드는 난이도가 높은 메서드이므로 꼭 직접 값을 변경해가면서 실행해보시길 바랍니다.
'파이썬완전정복-Pandas DataFrame > 16. 시간' 카테고리의 다른 글
| Pandas DataFrame 16-10 period로 변환 (to_period) (0) | 2022.02.17 |
|---|---|
| Pandas DataFrame 16-09 기간/데이터 쉬프트 (shift) (0) | 2022.02.17 |
| Pandas DataFrame 16-07 인덱스나누기[리샘플링] (asfreq) (0) | 2022.02.17 |
| Pandas DataFrame 16-06 TimeStamp변환(to_timestamp) (0) | 2022.02.17 |
| Pandas DataFrame 16-05 Timezone설정[표준시간대] (tz_localize) (0) | 2022.02.17 |