19-07 html으로 변환(to_html)
DataFrame.to_html(buf=None, columns=None, col_space=None, header=True, index=True, na_rep='NaN', formatters=None, float_format=None, sparsify=None, index_names=True, justify=None, max_rows=None, max_cols=None, show_dimensions=False, decimal='.', bold_rows=True, classes=None, escape=True, notebook=False, border=None, table_id=None, render_links=False, encoding=None)
개요
to_html메서드는 데이터프레임 객체를 html 문법으로 변환하는 메서드 입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.(buf=None, columns=None, col_space=None, header=True, index=True, na_rep='NaN', formatters=None, float_format=None, sparsify=None, index_names=True, justify=None, max_rows=None, max_cols=None, show_dimensions=False, decimal='.', bold_rows=True, classes=None, escape=True, notebook=False, border=None, table_id=None, render_links=False, encoding=None)
buf : 저장할 버퍼 입니다. None이면 문자열로 출력됩니다.
columns : 출력할 열을 지정합니다.
col_space : 열 너비를 지정합니다. 픽셀 단위 입니다.
header / index : 열/행 레이블의 출력 여부 입니다. False이면 출력하지 않습니다.
na_rep : 결측값의 표현 방식 입니다.
formatters : 포매터 함수를 통해 값의 포맷을 설정합니다. .format() 메서드도 사용 가능합니다.
float_format : 소수점 단위 자리수를 지정합니다. 기본은 마침표( . ) 입니다. sparsify : 각 행의 모든 다중 인덱스 키를 인쇄하려면 계층적 인덱스가 있는 DataFrame에 대해 False로 설정합니다.
index_names : 인덱스명을 출력할지를 정합니다.
justify : 정렬 방식을 지정합니다.
maxrows : 최대 출력할 줄 수를 지정합니다. 초과되는 줄은 ( ... )형태로 축약됩니다.
maxcols : 최대 출력할 열 수를 지정합니다. 초과되는 줄은 ( ... )형태로 축약됩니다.
minrow : maxrows로인해 잘린 표현을 표시할 수 입니다.
show_dimensions : 출력된 html 객체 아래에 데이터 객체의 차원을 출력합니다.
decimal : 1000단위 구분기호로 인식되는 문자를 지정합니다.
bold_rows : 출력에서 행 레이블을 굵게할지 여부입니다. 기본은 True입니다.
classes 결과 html의 table에 적용할 css 클래스를 지정합니다.
escape : 문자 <, > 및 &를 HTML 안전 시퀀스로 변환합니다. 즉 문자를 HTML 문법이 아닌 문자 그대로 출력합니다.
notebook : 생성된 HTML이 IPython Notebook용인지 여부입니다. 기본은 False입니다.
border : 테두리의 두께를 지정합니다.
encoding : 인코딩을 지정합니다.
table_id : css의 table id를 설정합니다.
render_links : url을 html 링크로 변환합니다.
예시
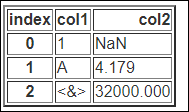
먼저 기본적인 사용법 예시를위하여 3x2 짜리 데이터를 만들어 보겠습니다.
data = [[1,np.NaN],['A',4.179],['<&>',32000]]
df = pd.DataFrame(data,columns=['col1','col2'])
df=df.rename_axis(columns='index')
print(df)
>>
index col1 col2
0 1 NaN
1 A 4.179
2 <&> 32000.000
기본적인 사용법
기본적으로 아무 입력값 없이 실행 할 경우 str 형식으로 반환됩니다.
print(df.to_html())
>>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th>index</th>
<th>col1</th>
<th>col2</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1</td>
<td>NaN</td>
</tr>
<tr>
<th>1</th>
<td>A</td>
<td>4.179</td>
</tr>
<tr>
<th>2</th>
<td><&></td>
<td>32000.000</td>
</tr>
</tbody>
</table>

columns인수의 사용
columns인수는 출력할 열을 지정합니다. 리스트 형태로 입력이 가능합니다.
print(df.to_html(columns=['col1']))
col1열만 출력되는 것을 확인할 수 있습니다.
col_space인수의 사용
col_space인수는 열의 수와 같은 크기의 리스트를 이용해 각 열의 크기를 지정할 수 있습니다.
print(df.to_html(col_space=[100,200]))
열의 크기가 100픽셀 x 200픽셀로 변경된 것을 알 수 있습니다.
header / index 인수의 사용
header / index 인수는 각각 열/행 레이블의 출력 여부를 지정하는 인수 입니다. 기본값은 True입니다.
print(df.to_html(header=False, index=False))
둘다 False로 입력하자 인덱스가 출력되지 않은것을 확인할 수 있습니다.
na_rep 인수의 사용
na_rep인수는 결측값을 어떤 문자로 출력할지 지정하는 메서드 입니다.
print(df.to_html(na_rep="결측값"))
NaN이 결측값으로 출력된 것을 확인할 수 있습니다.
formatters 인수의 사용
formatter 인수에 함수를 이용하여 값의 포맷을 변경할 수 있습니다.
예시를 위해 datetime을 포함하는 데이터프레임 객체를 생성하겠습니다.
time = pd.to_datetime(['16:04:33.500','17:30:00.000'],format='%H:%M:%S.%f')
x = pd.DataFrame({'col':time})
print(x)
>>
col
0 1900-01-01 16:04:33.500
1 1900-01-01 17:30:00.000
이제 형식을 변환하는 함수를 작성하여 formatter함수에 적용해보겠습니다.
def format_func(x):
return x.strftime('%H:%M')
result = x.to_html(formatters={'col':format_func})
print(result)
시:분:초:각초 형식의 데이터를 시:분 형태로 html 변환이 실행된 것을 확인할 수 있습니다.

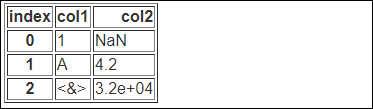
float_format인수의 사용
float_format인수를 이용해 소수점 표현방식을 포매터 함수를 이용해서 지정할 수 있습니다.
print(df.to_html(float_format='{0:.2g}'.format))
4.197이 표현식에따라 4.2로, 32000이 표현식에 따라 3.2e+04로 출력된 것을 확인할 수 있습니다.
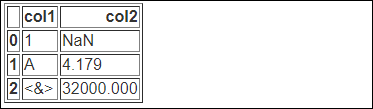
index_names 인수의 사용
index_names 인수를 이용해 인덱스명의 출력 여부를 지정할 수 있습니다. 기본값은 True 입니다.
print(df.to_html(index_names=False))
인덱스명으로 입력되었던 Index가 출력되지 않은 것을 확인할 수 있습니다.
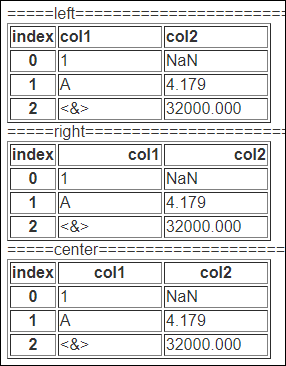
justify 인수의 사용
justify 인수를 통해 정렬 방식을 지정할 수 있습니다.
{left / right / center / justify / justify-all / start / end / inherit / match-parent / initial / unset}
print('====='+'left'+'='*20) # 구분을 위해 입력한 값입니다.
print(df.to_html(col_space=[100,100], justify='left'))
print('====='+'right'+'='*20)
print(df.to_html(col_space=[100,100], justify='right'))
print('====='+'center'+'='*20)
print(df.to_html(col_space=[100,100], justify='center'))
인덱스의 정렬방식이 각각 왼쪽정렬, 오른쪽 정렬, 가운데 정렬이 된것을 확인할 수 있습니다.
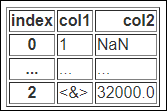
maxrow 인수의 사용
maxrow인수는 최대 출력줄 수를 지정하는 인수입니다. 초과되는 수의 열은 (...) 형태로 축약됩니다.
print(df.to_html(max_rows=2))
maxcols 인수의 사용
maxcol인수는 최대 출력열 수를 지정하는 인수입니다. 초과되는 수의 열은 (...) 형태로 축약됩니다.
print(df.to_html(max_cols=1))
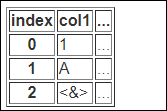
show_dimensions 인수의 사용
show_dimensions 인수를 통해 데이터 객체의 차원을 추가로 출력할 수 있습니다.
print(df.to_html(show_dimensions=True))
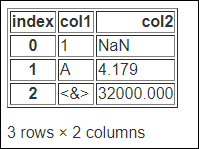
decimal 인수의 사용
decimal 인수를 이용하여 10,000 같이 1000단위수의 구분기호로 사용되는 콤마( , )를 다른 문자로 변경 할 수 있습니다.
print(df.to_html(decimal='_'))
1000단위 구분기호인 콤마( , )가 언더바( _ )로 변경된 것을 확인할 수 있습니다.
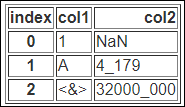
bold_rows인수의 사용
bold_rows인수를 이용해서 출력의 행 레이블을 굵게 설정할지 여부를 지정할 수 있습니다. 기본값은 True입니다.
print(df.to_html(bold_rows=False))
행 레이블이 기본값인 굵게 에서 보통으로 바뀐것을 확인할 수 있습니다.
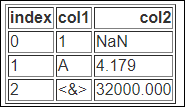
classes 인수의 사용
classes인수를 이용해서 html의 table에 적용할 css 클래스를 지정할 수 있습니다.
print(df.to_html(classes='test'))
>>
<table border="1" class="dataframe test"> # class가 dataframe test로 설정됨.
<thead>
<tr style="text-align: right;">
...
</tr>
</tbody>
</table>
escape 인수의 사용
escape인수를 이용하여문자 <, > 및 &를 HTML 안전 시퀀스로 변환합니다.
즉, 문자를 HTML 문법이 아닌 문자 그대로 출력합니다. 기본값은 True 입니다.
print(df.to_html(escape=False))
기존 데이터의 <&>가 html 문법으로 출력되어 오류가 발생한 것을 확인 할 수 있습니다.
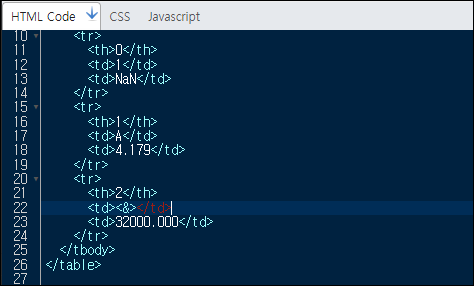
border 인수의 사용
border인수는 테두리의 두께를 지정하는 인수입니다.
print(df.to_html(border=2))
두께가 두껍게 출력된 것을 확인할 수 있습니다.
table_id 인수의 사용
table_id인수를 이용해 css로 table의 id를 설정할 수 있습니다.
print(df.to_html(table_id='test'))
>>
<table border="1" class="dataframe" id="test"> # table id가 설정됨
<thead>
<tr style="text-align: right;">
...
</tr>
</tbody>
</table>'파이썬완전정복-Pandas DataFrame > 19. 형식 변환' 카테고리의 다른 글
| Pandas DataFrame 19-08 string으로 변환(to_string) (0) | 2022.03.14 |
|---|---|
| Pandas DataFrame 19-06 pickle객체로변환 (to_pickle) (0) | 2022.03.14 |
| Pandas DataFrame 19-05 Markdown으로 변환 (to_markdown) (0) | 2022.03.14 |
| Pandas DataFrame 19-04 dict로 변환 (to_dict) (0) | 2022.03.14 |
| Pandas DataFrame 19-03 클립보드에 저장 (to_clipboard) (0) | 2022.03.14 |