02-10. 기간이동 계산 (rolling)
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None, method='single')
개요
rolling 메서드는 현재 열에 대하여 일정 크기의 창(window)를 이용하여 그 window안의 값을 추가 메서드를 통해 계산하는 메서드 입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None, method='single')
window : 계산할 창(window)의 크기 입니다. 열 기준으로 계산할 경우 행의 수입니다.
min_periods : 계산할 최소 크기(기간) 입니다. window 안의 값의 수가 min_periods의 값보다 작을경우 NaN을 출력합니다.
기본적으로 window 크기와 동일합니다.
center : {True / False} 레이블을 window의 중간에 둘지 여부입니다. 기본값은 False로 레이블이 창 우측에 위치합니다.
win_type : {'triang' / 'gaussian' / ...} 가중치를 넣어 계산할 경우 계산 방식 입니다. 때에따라 연산 메서드에 추가 인수를 지정해야할수도 있습니다.
on : 시계열 인덱스나, 시계열과 유사한 열이 있을 경우 이 열을 기준으로 rolling을 수행할 수 있습니다.
axis : 계산의 기준이 될 축입니다.
closed : {'left' / 'right' / 'both' / 'neither'} window가 닫히는 방향입니다. 자세한건 아래 예시 참고바랍니다
method :{'single' / 'table'} numba 를 이용하여 테이블 계산을 진행하여 속도를 높힐지 여부입니다. 현재 'single'만 사용가능합니다.
※ method 인수의 numba 사용은 02-09 누적계산(expending)에서 자세히 다루고 있습니다.
예시
먼저 기본적인 사용법 예시를위하여 6x2 짜리 데이터를 만들어 보겠습니다.
col2는 on 인수의 사용을 위해 시계열 값으로 작성하였으나, 일반 계산에서는 진행되지 않습니다.
period = pd.period_range(start='2022-01-13 00:00:00',end='2022-01-13 02:30:00',freq='30T')
data = {'col1':[1,2,3,4,5,6],'col2':period}
idx = ['row1','row2','row3','row4','row5','row6']
df = pd.DataFrame(data= data, index = idx)
print(df)
>>
col1 col2
row1 1 2022-01-13 00:00
row2 2 2022-01-13 00:30
row3 3 2022-01-13 01:00
row4 4 2022-01-13 01:30
row5 5 2022-01-13 02:00
row6 6 2022-01-13 02:30
기본적인 사용법
window 크기를 지정해주면, 현재 행 이전으로 window 크기 만큼의 계산을 수행합니다.
print(df.rolling(window=3).sum()) # 뒤에 추가 메서드를 이용하여 연산을 지정해주어야합니다.
>>
col1
row1 NaN # min_period의 크기는 지정하지 않을경우 window크기와 동일하므로 NaN출력
row2 NaN
row3 6.0 # 1행, 2행, 3행의 sum값 출력
row4 9.0 # 2행, 3행, 4행의 sum값 출력
row5 12.0
row6 15.0
closed인수의 사용
closed는 계산의 닫는 위치를 지정합니다. 만약 6행을 기준으로 window=3을 계산한다고 하면 아래와 같은 범위로 window경계가 지정됩니다.
left : 3 ≤ x < 6
right : 3 < x ≤ 6
both : 3 ≤ x ≤ 6
neither : 3 < x < 6
closed='left'인 경우
print(df.rolling(window=3, closed='left').sum())
>>
col1
row1 NaN
row2 NaN
row3 NaN
row4 6.0
row5 9.0
row6 12.0
closed='right'인 경우
print(df.rolling(window=3, closed='right').sum())
>>
col1
row1 NaN
row2 NaN
row3 6.0
row4 9.0
row5 12.0
row6 15.0
closed='both'인 경우
print(df.rolling(window=3, closed='both').sum())
>>
col1
row1 NaN
row2 NaN
row3 6.0
row4 10.0
row5 14.0
row6 18.0closed='neither'인 경우 min_period보다 window 크기가 작으므로 min_period를 지정해주어야합니다.
print(df.rolling(window=3, closed='neither').sum())
>>
col1
row1 NaN
row2 NaN
row3 NaN
row4 NaN
row5 NaN
row6 NaN
print(df.rolling(window=3, closed='neither',min_periods=2).sum()) # min_period 지정
>>
col1
row1 NaN
row2 NaN
row3 3.0
row4 5.0
row5 7.0
row6 9.0
center인수의 사용
center을 이용하여 레이블이 window의 중앙에 올지를 정할 수 있습니다.
자세한건 아래 이미지를 참고하면 이해하기 쉽습니다.
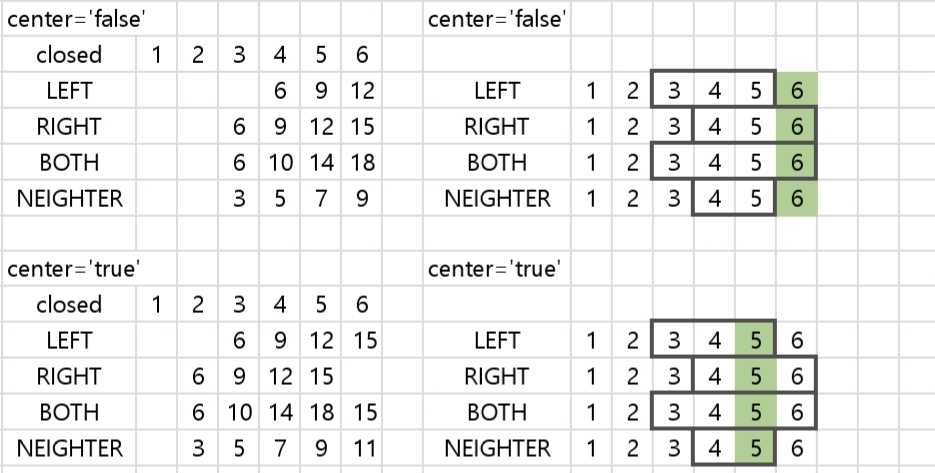
center=True인 경우 레이블이 window의 중앙에 위치한 것을 알 수 있습니다.
print(df.rolling(window=3, center=True).sum())
>>
col1
row1 NaN
row2 6.0
row3 9.0
row4 12.0
row5 15.0
row6 NaN
win_type인수의 사용
win_type을 지정할 경우 가중치를 주며 계산을 할 수 있습니다.
print(df.rolling(window=3, win_type='triang').sum()) # 삼각함수로 가중치 부여
>>
col1
row1 NaN
row2 NaN
row3 4.0
row4 6.0
row5 8.0
row6 10.0
print(df.rolling(window=3, win_type='gaussian').sum(std=3)) # 가우시안 분포로 가중치 부여
>>
col1
row1 NaN
row2 NaN
row3 5.783838
row4 8.675757
row5 11.567676
row6 14.459595
on 인수의 사용
on='col2'를 이용하여 col2열의 시계열 인덱스를 기준으로 rolling의 수행이 가능합니다.
print(df.rolling(window='60T',on='col2').sum())
>>
col1 col2
row1 1.0 2022-01-13 00:00 # col2를 기준으로 rolling이 수행됨
row2 3.0 2022-01-13 00:30
row3 5.0 2022-01-13 01:00
row4 7.0 2022-01-13 01:30
row5 9.0 2022-01-13 02:00
row6 11.0 2022-01-13 02:30'파이썬완전정복-Pandas DataFrame > 02. 객체내 연산' 카테고리의 다른 글
| Pandas DataFrame 02-12. 지수가중함수 (ewm) (0) | 2022.01.28 |
|---|---|
| Pandas DataFrame 02-11. 그룹화 계산 (groupby) (0) | 2022.01.28 |
| Pandas DataFrame 02-09. 누적 계산 (expanding) (0) | 2022.01.11 |
| Pandas DataFrame 02-08. 차이[백분률] (pct_change) (0) | 2022.01.09 |
| Pandas DataFrame 02-07. 차이[이산] (diff) (0) | 2022.01.09 |