이번장에는 저번에 만든 URL 파싱 -> 데이터프레임으로 변환하는 함수에서
원하는 종목과 기간으로 파싱할 수 있도록 함수를 만들어 보도록 한다.
저번 글 링크 >>
https://trading-for-chicken.tistory.com/6
03. OHLCV 데이터를 파싱해 Pandas Dataframe 형태로 만들기 -2
저번 글에서 데이터를 깔끔하게 파싱하는데 성공하였다. 이제 Pandas Dataframe 형태로 변환하도록 하자. 저번 글 링크>> https://trading-for-chicken.tistory.com/5 02. OHLCV 데이터를 파싱해 Pandas Datafram..
trading-for-chicken.tistory.com
먼저 URL을 보면
이런 형태이다. 여기서 symbol 값은 원하는 종목코드로 변환만 해주면 기존 URL 형태와 똑같은 형태로 값만 다르게 나온다. 그러므로 단순히 위 url의 005930만 변수 code로 변경해주면 된다. 한번 변경해보고 ohlcv_data(code='003550')
을 실행해보자(*003550은 LG전자의 종목코드)
def ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day'):
# 005930만 str(code)로 변경, 문자열로 입력돼야하기 때문에 str을 사용.
url = 'https://api.finance.naver.com/siseJson.naver?symbol='+str(code)+'&requestType=1&startTime=20190624&endTime=20210901&timeframe=day'
res = urlopen(url, context=ssl.create_default_context())
soup = BeautifulSoup(res.read(), 'html.parser', from_encoding='utf-8')
data = str(soup).split('],')
df = pd.DataFrame(columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume'])
for i in range(1,len(data)):
date = data[i].split(', ')[0].split('["')[1].split('"')[0]
open = data[i].split(', ')[1]
high = data[i].split(', ')[2]
close = data[i].split(', ')[3]
low = data[i].split(', ')[4]
volume = data[i].split(', ')[5]
list = [date, open, high, low, close, volume]
df = df.append(pd.Series(list, index=df.columns), ignore_index=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
df = df.astype({'Open':'int','High':'int','Low':'int','Close':'int','Volume':'int'})
df = df.sort_index(ascending=True)
return df
if __name__ == '__main__':
print(ohlcv_data(code='003550'))아래와 같이 LG전자의 종목코드가 출력된 것을 확인할 수 있다.

다음으로 다시 URL을 보면
https://api.finance.naver.com/siseJson.naver?symbol=005930&requestType=1&startTime=20190624&endTime=20210901&timeframe=day
timeframe도 단순히 day, week, month만 입력해주면 URL 페이지 형식은 똑같고 알아서 주봉, 월봉 데이터로 변경되기 때문에 단순히 위 URL의 day부분만 변수 timeframe으로 설정해주면 된다. 한번 변경해보고
ohlcv_data(code='003550', timeframe='month')로 실행해보자
def ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day'):
# url의 day를 변수 timeframe으로 변경
url = 'https://api.finance.naver.com/siseJson.naver?symbol='+str(code)+'&requestType=1&startTime=20190624&endTime=20210901&timeframe='+str(timeframe)
res = urlopen(url, context=ssl.create_default_context())
soup = BeautifulSoup(res.read(), 'html.parser', from_encoding='utf-8')
data = str(soup).split('],')
df = pd.DataFrame(columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume'])
for i in range(1,len(data)):
date = data[i].split(', ')[0].split('["')[1].split('"')[0]
open = data[i].split(', ')[1]
high = data[i].split(', ')[2]
close = data[i].split(', ')[3]
low = data[i].split(', ')[4]
volume = data[i].split(', ')[5]
list = [date, open, high, low, close, volume]
df = df.append(pd.Series(list, index=df.columns), ignore_index=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
df = df.astype({'Open':'int','High':'int','Low':'int','Close':'int','Volume':'int'})
df = df.sort_index(ascending=True)
return df
if __name__ == '__main__':
print(ohlcv_data(code='003550', timeframe='month')) # timeframe을 'month'로 실행아래와 같이 dataframe이 월봉으로 출력된것을 확인할 수 있다.

endtime의 경우 날짜를 입력하면 그 날짜를 endtime으로하고 입력하지 않으면 기본값인 'today'가 입력되어 오늘 날짜가 입력 되도록 할 것이다. 오늘 날짜를 가져와야 하기 때문에, from datetime import datetime 로 datetime을 import 해주자. 여기서 원하는 포맷으로 출력하는 함수인 strftime() 함수를 이용하면 된다. 아래와 같이 실행해보면
원하는 형태로 출력 됨을 알 수 있다.
if __name__ == '__main__':
print(datetime.today().strftime('%Y%m%d')) # YYYYMMDD 형태
위 내용을 함수에 적용하고 아무 날짜 (20200310)으로 ohlcv_data함수를 실행해보자.
def ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day'):
if endtime == 'today': #endtime이 today일 경우
endtime == datetime.today().strftime('%Y%m%d') # yyyymmdd 형태로 변환된 오늘 날짜 입력
# endtime을 변수에 할당.
url = 'https://api.finance.naver.com/siseJson.naver?symbol='+str(code)+'&requestType=1&startTime=20190624&endTime='+str(endtime)+'&timeframe='+str(timeframe)
res = urlopen(url, context=ssl.create_default_context())
soup = BeautifulSoup(res.read(), 'html.parser', from_encoding='utf-8')
data = str(soup).split('],')
df = pd.DataFrame(columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume'])
for i in range(1,len(data)):
date = data[i].split(', ')[0].split('["')[1].split('"')[0]
open = data[i].split(', ')[1]
high = data[i].split(', ')[2]
close = data[i].split(', ')[3]
low = data[i].split(', ')[4]
volume = data[i].split(', ')[5]
list = [date, open, high, low, close, volume]
df = df.append(pd.Series(list, index=df.columns), ignore_index=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
df = df.astype({'Open':'int','High':'int','Low':'int','Close':'int','Volume':'int'})
df = df.sort_index(ascending=True)
return df
if __name__ == '__main__':
print(ohlcv_data(code='003550',endtime='20200310', timeframe='day'))아래와 같이 제대로 원하는 날짜까지 출력한 것을 알 수 있다.
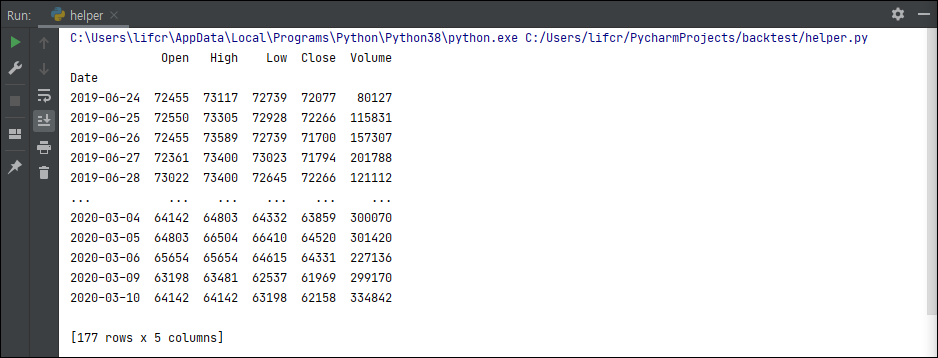
이제 마지막으로 starttime의 설정이다. starttime의 경우 날짜를 입력하면 그날부터 파싱을 수행하고, 따로 입력하지 않으면 endtime으로부터 1년전(365) 값부터 파싱하도록 할 것이다. datetime은 timedelta함수를 이용해서 더하고 뺴는것이 가능하다. 일단 순서는 아래와 같다
1. str로 입력된 날짜 자료형을 datetime 자료형으로 변경
2. timedelta를 이용해 1년전(365일) 값 계산
3. 다시 str(yyyymmdd) 형식으로 변경
str 자료형을 datetime 자료형으로 변경하려면 datetime에서 strptime 메서드를 이용하면 된다.
datetime.strptime('날짜string', '날짜형식')
from datetime import datetime
from datetime import timedelta
if __name__ == '__main__':
date = datetime.strptime('20201231', '%Y%m%d') # str 형식을 datetime 형식으로 변경
print(date)위 코드를 실행해보면 2020-12-31 00:00:00 으로 datatime 형태로 변경 된것을 확인할 수 있다.
이제 여기에 timedelta(days=일수) 함수를 이용해서 1년전 날짜를 datetime형태로 만들어보자
from datetime import datetime
from datetime import timedelta
if __name__ == '__main__':
date = datetime.strptime('20201231','%Y%m%d')-timedelta(days=365)
print(date)위 코드를 실행해보면 2020-01-01 00:00:00 으로 datatime 형태로 변경 된것을 확인할 수 있다.
이제 이 datetime 형식을 url 에 적용할 수 있도록 다시 적용할 수 있도록 str 형식(yyyymmdd)로 바꿔주도록 한다.
위에 endtime에 썻던 함수를 그대로 쓴다.
from datetime import datetime
from datetime import timedelta
if __name__ == '__main__':
date = datetime.strptime('20201231','%Y%m%d')-timedelta(days=365)
starttime = date.strftime('%Y%m%d')
print(starttime)위 코드를 실행해보면 20200101 로 str형태로 변경 된것을 확인할 수 있다. 우리는 endtime 값에서 365일을 뺄 것이므로 위 함수에서 '20201231' 부분을 변수 endtime으로 넣어주기만 하면된다.
이제 이 함수를 ohlcv_data 함수에 적용후 아래 함수를 실행해보자
ohlcv_data(code='003550',starttime='default',endtime='20200310', timeframe='day')
def ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day'):
if endtime == 'today':
endtime = datetime.today().strftime('%Y%m%d')
if starttime == 'default':
date = datetime.strptime(endtime,'%Y%m%d')-timedelta(days=365)
starttime = date.strftime('%Y%m%d')
url = 'https://api.finance.naver.com/siseJson.naver?symbol='+str(code)+'&requestType=1&startTime='+str(starttime)+'&endTime='+str(endtime)+'&timeframe='+str(timeframe)
res = urlopen(url, context=ssl.create_default_context())
soup = BeautifulSoup(res.read(), 'html.parser', from_encoding='utf-8')
data = str(soup).split('],')
df = pd.DataFrame(columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume'])
for i in range(1,len(data)):
date = data[i].split(', ')[0].split('["')[1].split('"')[0]
open = data[i].split(', ')[1]
high = data[i].split(', ')[2]
close = data[i].split(', ')[3]
low = data[i].split(', ')[4]
volume = data[i].split(', ')[5]
list = [date, open, high, low, close, volume]
df = df.append(pd.Series(list, index=df.columns), ignore_index=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
df = df.astype({'Open':'int','High':'int','Low':'int','Close':'int','Volume':'int'})
df = df.sort_index(ascending=True)
return df
if __name__ == '__main__':
print(ohlcv_data(code='003550',endtime='20200310', timeframe='day'))아래와같이 원하는대로 출력이 되는것을 확인 할 수 있다.
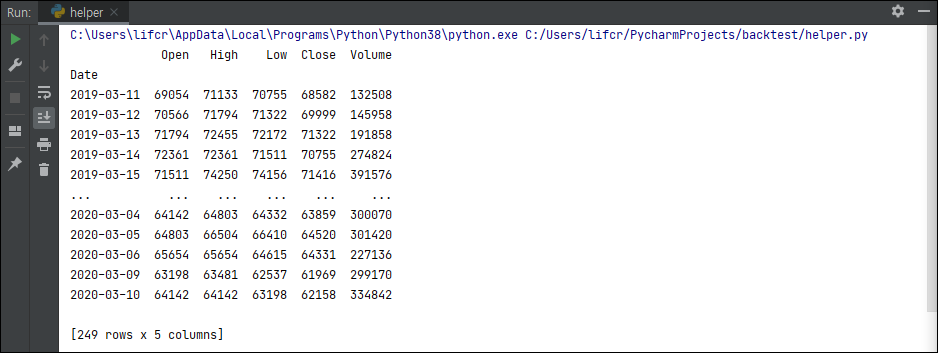
이로써 네이버 금융에서 data를 파싱해서 mplfinance나 backtrader에서 사용가능한 형태의
pandas dataframe로 바꿔주는 함수인
ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day') 를 완성하였다!
전체 코드
from bs4 import BeautifulSoup
from urllib.request import urlopen
import ssl
import pandas as pd
from datetime import datetime
from datetime import timedelta
def ohlcv_data(code='005930',starttime='default',endtime='today',timeframe='day'):
if endtime == 'today':
endtime = datetime.today().strftime('%Y%m%d')
if starttime == 'default':
date = datetime.strptime(endtime,'%Y%m%d')-timedelta(days=365)
starttime = date.strftime('%Y%m%d')
url = 'https://api.finance.naver.com/siseJson.naver?symbol='+str(code)+'&requestType=1&startTime='+str(starttime)+'&endTime='+str(endtime)+'&timeframe='+str(timeframe)
res = urlopen(url, context=ssl.create_default_context())
soup = BeautifulSoup(res.read(), 'html.parser', from_encoding='utf-8')
data = str(soup).split('],')
df = pd.DataFrame(columns=['Date', 'Open', 'High', 'Low', 'Close', 'Volume'])
for i in range(1,len(data)):
date = data[i].split(', ')[0].split('["')[1].split('"')[0]
open = data[i].split(', ')[1]
high = data[i].split(', ')[2]
close = data[i].split(', ')[3]
low = data[i].split(', ')[4]
volume = data[i].split(', ')[5]
list = [date, open, high, low, close, volume]
df = df.append(pd.Series(list, index=df.columns), ignore_index=True)
df['Date'] = pd.to_datetime(df['Date'])
df = df.set_index('Date')
df = df.astype({'Open':'int','High':'int','Low':'int','Close':'int','Volume':'int'})
df = df.sort_index(ascending=True)
return df'BeautifulSoup을 이용한 웹 크롤링' 카테고리의 다른 글
| 03. OHLCV 데이터를 파싱해 Pandas Dataframe 형태로 만들기 -2 (0) | 2021.09.01 |
|---|---|
| 02. OHLCV 데이터를 파싱해 Pandas Dataframe 형태로 만들기 -1 (0) | 2021.09.01 |
| 01. Naver Finance에서 크롤링할 URL 찾기 (0) | 2021.09.01 |