15-05 상관계수 (corr / corrwith)
DataFrame.corr(method='pearson', min_periods=1)
DataFrame.corrwith(other, axis=0, drop=False, method='pearson')
개요
corr메서드는 각 열 간의 상관 계수를 반환하는 메서드입니다.
corrwith메서드는 두 DataFrame객체의 동일한 행/열 간의 상관 계수를 반환하는 메서드입니다.
상관계수 산정 방식에는 피어슨 상관계수, 켄달-타우 상관계수, 스피어먼 상관계수를 사용합니다.
[피어슨 상관계수]
피어슨 상관계수는 두 변수 간의 선형 상관관계를 계량화 한 수치입니다. 코시-슈바르츠 부등식에 의해 +1과 -1사이의 값을 가집니다.
+1의 경우 완벽한 양의 선형 상관 관계, -1의 경우 완벽한 음의 상관관계, 0의 경우 선형 상관관계를 갖지 않습니다.
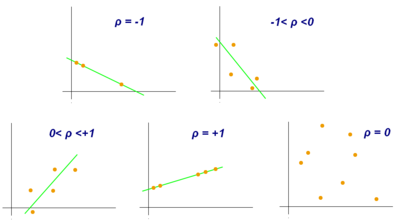
서로 다른 상관계수 값을 갖는 산포도 다이어그램의 예
※출처 : 위키피디아 '피어슨 상관계수' 항목
[켄달-타우상관계수]
켄달-타우 상관계수는 두 변수들간의 순위를 비교해서 연관성을 계산하는 방식입니다.
예를들어 어린이의 나이와 키에 대한 아래와 같은 순위 데이터를 보면, 나이순위에 따라 키의 순위가 동일한 것을 알 수 있습니다.
| 나이 | 1 | 3 | 4 | 2 | 5 |
| 키 | 1 | 3 | 4 | 2 | 5 |
이런 경우 켄달-타우 상관계수의 경우 완벽한 양의 상관 계수인 +1이 됩니다.
[스피어먼 상관계수]
스피어먼 상관계수는 두 변수의 순위 값 사이의 피어슨 상관 계수와 같습니다.
즉, 순서척도가 적용되는 경우에는 스피어먼 상관계수가, 간격척도가 적용되는 경우에는 피어슨 상관계수가 적용됩니다.
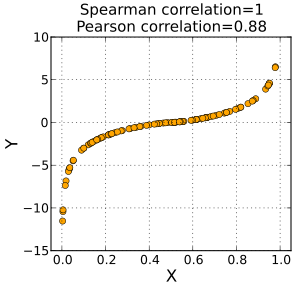
두 변수가 선형관계가 아니어도 스피어먼 상관계수는 1이 될수 있습니다. 단순히 순위간의 상관계수이기 때문입니다. ※ 출처 : 위키피디아 - '스피어먼 상관계수' 항목
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.corr(method='pearson', min_periods=1)
method : {pearson / kendall / spearman} 적용할 상관계수 방식입니다.
min_periods : 유효한 결과를 얻기위한 최소 값의 수 입니다. (피어슨, 스피어먼만 사용가능)
df.corrwith(other, axis=0, drop=False, method='pearson')
other : 동일한 이름의 행/열을 비교할 다른 객체입니다.
axis : {0 : index / 1 : columns} 비교할 축 입니다. 기본적으로 0으로 인덱스끼리 비교합니다.
drop : 동일한 이름의 행/열이 없을경우 NaN을 출력하는데, 이를 출력하지 않을지 여부입니다.
method : {pearson / kendall / spearman} 적용할 상관계수 방식입니다.
예시1 [corr]
먼저 corr 메서드의 기본적인 사용법 예시를 위해 6x3짜리 객체를 생성하겠습니다.
col1 = [1,2,3,4,5,6]
col2 = [1,4,2,8,16,32]
col3 = [6,5,4,3,2,1]
data = {"col1":col1,"col2":col2,"col3":col3}
df = pd.DataFrame(data)
print(df)
>>
col1 col2 col3
0 1 1 6
1 2 4 5
2 3 2 4
3 4 8 3
4 5 16 2
5 6 32 1
피어슨 상관계수
피어슨 상관계수의 경우 method='pearson'을 사용하며, 두 변수의 선형 상관계수를 의미합니다.
print(df.corr(method='pearson'))
>>
col1 col2 col3
col1 1.000000 0.887739 -1.000000
col2 0.887739 1.000000 -0.887739
col3 -1.000000 -0.887739 1.000000
col1이 증가할 경우 col2는 대체로 증가하는 경향을 가지기에 0<p<1의 값을 가지며,
col1이 증가할 경우 col3은 완벽히 감소하기 때문에 p=-1의 값을 가집니다
켄달-타우 상관계수
켄달-타우 상관계수는 두 순위간의 상관 계수를 의미합니다.
print(df.corr(method='kendall'))
>>
col1 col2 col3
col1 1.000000 0.866667 -1.000000
col2 0.866667 1.000000 -0.866667
col3 -1.000000 -0.866667 1.000000
col1의 순위는 col2의 순위와 대체로 일치 하기에 0<p<1의 값을 가지며,
col1의 순위는 col3의 순위와 완벽히 반대이기 때문에 p=-1의 값을 가집니다
스피어먼 상관계수
스피어먼 상관계수는 두 변수의 순위의 피어슨 상관계수를 의미합니다.
print(df.corr(method='spearman'))
>>
col1 col2 col3
col1 1.000000 0.942857 -1.000000
col2 0.942857 1.000000 -0.942857
col3 -1.000000 -0.942857 1.000000
col1의 변수들의 순위는 col2의 변수들의 순위와 대체로 일치 하기에 두 변수의 순위의 피어슨 상관계수는 0<p<1의 값을 가지며,
col1의 변수들의 순위는 col3의 변수들의 순위와 완벽히 반대이기 때문에 두 변수의 순위의 피어슨 상관계수는p=-1의 값을 가집니다
예시2 [corrwith]
corrwith 메서드의 기본적인 사용법 예시를 위해 6x2짜리 객체 2개를 생성하겠습니다.
data1 = {"col1":[1,2,3,4,5,6],"col2":[1,4,2,8,16,32]}
data2 = {"col1":[6,5,4,3,2,1],"col3":[3,6,1,2,5,9]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
기본적인 사용법
df1과 df2는 col1이라는 열을 갖지만 모두가 col2, col3을 갖진 않습니다.
이 상태에서 corrwith을 사용할 경우 col1에 대해서만 상관관계 계산이 진행됩니다.
print(df1.corrwith(other = df2, method = `pearson`))
>>
col1 -1.0
col2 NaN
col3 NaN
dtype: float64
drop = True를 할 경우 쌍을 이루지 못하여 NaN을 반환한 열을 제외하고 출력합니다.
print(df1.corrwith(other = df2, method = `pearson`, drop = True))
>>
col1 -1.0
dtype: float64
method의 경우 corr 메서드와 동일하기 때문에 생략합니다.
'파이썬완전정복-Pandas DataFrame > 15. 통계(심화)' 카테고리의 다른 글
| Pandas DataFrame 15-04 왜도[비대칭도] (skew) (0) | 2022.02.08 |
|---|---|
| Pandas DataFrame 15-03 표준오차 (sem) (0) | 2022.02.08 |
| Pandas DataFrame 15-02 첨도 (kurt / kurtosis) (0) | 2022.02.08 |
| Pandas DataFrame 15-01 공분산 (cov) (0) | 2022.02.08 |