19-01 csv으로 변환 (to_csv)
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)
개요
to_csv 메서드는 데이터프레임 객체를 csv 형식으로 변환하는 메서드입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)
path_or_buf : csv파일이 생성되는 경로와 파일명 입니다.
sep : csv 파일의 구분자 입니다. 기본값은 ' , ' 입니다.
na_rep : 결측값을 어떻게 출력할지 지정할 수 있습니다. 기본값은 공백 입니다.
float_format : 부동소수점의 경우 어떤 형식으로 출력할지 지정할 수 있습니다.
columns : 출력할 열을 지정하는 인수 입니다.
header : 열 이름을 설정합니다. False일 경우 열 이름을 출력하지 않습니다.
index : 인덱스의 출력 여부 입니다. False일 경우 인덱스를 출력하지 않습니다.
index_label : 인덱스의 레이블(인덱스명)을 설정합니다.
mode : {'w' / 'a'} 쓰기 모드를 지정합니다. a로 지정할 경우 기존 파일 아래에 값을 추가하여 입력하게됩니다.
encoding : 인코딩 설정입니다. 기본값은 utf-8입니다.
compression : {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None} 압축 설정을 지정합니다. 기본값은 'infer'로 적절한 압축형식을 추론합니다.
quoting : 값에 대해서 인용구 설정을 할 수 있습니다. 어떤 값에 대해서 인용구를 설정할지는 아래와 같습니다.
{0 : MINIMAL 문자와 특수문자 / 1 : ALL 모든필드 / 2 : NONNUMERIC 숫자가 아닌것 / 3 : NONE 안함}
quotechar : quoting에서 지정한 인용구에 대해서 인용구에 사용할 문자를 지정합니다. 기본값은 쌍따옴표 입니다.
chunksize : 한번에 불러올 행의 수를 지정합니다. 예를들어 100을 입력할 경우 한번에 100행씩 변환합니다. 속도 향상에 기여합니다.
date_format : 값이 시계열(datetime) 데이터인 경우 그 값의 포맷을 지정합니다.(예 : '%Y-%m')
doublequoto : 값중에 quotechar과 같은 값이 있을때, 그 값을 인용구 처리할지의 여부 입니다.
escapechar : doublequoto=False인 경우 인용구와 중복되는 그 값을 어떤 값으로 변경할지 여부입니다.
decimal : 자리수로 쓰이는 문자를 지정합니다.즉, 100,000의 경우 decimal="."으로 할 경우100.000으로 표시합니다.
errors : 인코딩 오류에 대해서 오류 처리를 정할 수 있습니다. 가능한 값은 아래와 같습니다.
{strict : 인코딩 오류에 ValueError 발생 / ignore : 무시 / replace 잘못된 데이터를 대체마커 '?' 지정 / ...}
더 많은 값에 대해서는 python library 의 strict 문서 참고 바랍니다.
storage_options : 특정 스토리지 연결에 적합한 추가 옵션, 예: 호스트, 포트, 사용자 이름, 비밀번호 등을 지정합니다.
예시
먼저 기본적인 사용법 예시를위하여 3x2 짜리 데이터를 만들어 보겠습니다.
data = [[1,np.NaN],['A',4.1],['-','3']]
df = pd.DataFrame(data)
address = 'C:\\Users\\lifcr\\OneDrive\\바탕 화면\\pandas\\' #기본 경로 설정해줌(코딩이 길어지므로)
>>
0 1
0 1 NaN # 결측치 NaN 포함
1 A 4.1 # 문자 A, 부동소수점 4.1 포함
2 - 3 # 문자 - 포함
기본적인 사용법
기본적으로 path_or_buf에 경로와 파일 이름을 지정해주면, 해당 경로에 df가 변환된 csv파일이 생성됩니다.
df.to_csv(path_or_buf=address+'test1.csv')
결과는 아래와 같습니다.(엑셀로 실행)
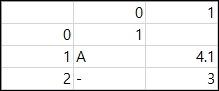
sep 인수의 사용
sep 인수는 csv파일의 구분자를 설정해 줍니다. 기본값은 쉼표(,)입니다.
df.to_csv(path_or_buf=address+'test2.csv', sep='-')
결과는 아래와 같습니다. (메모장으로 실행)
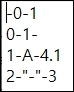
na_rep인수의 사용
na_rep인수는 데이터의 결측값(NaN)을 어떤 값으로 출력할지를 지정할 수 있습니다.
df.to_csv(path_or_buf=address+'test3.csv', na_rep=100)
결과는 아래와 같습니다. NaN이 100으로 변경된것을 확인할 수 있습니다.
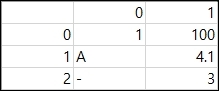
float_format 인수의 사용
float_format인수는 부동소수점 형식 데이터의 출력 포맷을 설정할 수 있습니다.
만약 값으로 그냥 string 형태의 값을 입력할 경우 해당 값이 출력됩니다.
df.to_csv(path_or_buf=address+'test4.csv', float_format='%.2f')
결과는 아래와 같습니다. 소수점 형식이 4.1에서 4.10으로 적용되었습니다.

columns인수의 사용
columns인수는 출력할 대상 열을 지정하는 인수입니다. 따로 입력하지 않는경우 모든 열이 csv변환 됩니다.
df.to_csv(path_or_buf=address+'test5.csv', columns=[0]
결과는 아래와 같습니다. 0열만 csv로 변환된것을 확인할 수 있습니다.
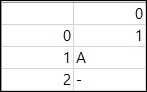
header 인수의 사용
header인수는 열의 이름을 지정하는 인수입니다. False일 경우 열 이름을 출력하지 않습니다.
df.to_csv(path_or_buf=address+'test6.csv', header=['col1','col2'])
결과는 아래와 같습니다. 열 0, 1 이 col1, col2로 변경되었습니다.
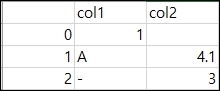
index인수의 사용
index인수는 인덱스의 출력 여부를 지정할 수 있습니다. 기본값은 True 입니다.
df.to_csv(path_or_buf=address+'test7.csv', index=False)
결과는 아래와 같습니다. index=False로 인덱스가 출력되지 않았습니다.
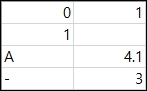
index_label인수의 사용
index_lable인수는 출력되는 csv파일의 인덱스명을 지정하는 인수 입니다.
df.to_csv(path_or_buf=address+'test8.csv', index_label=['index'])
결과는 아래와 같습니다. 인덱스에 대해서 맨위에 인덱스명이 지정되었습니다.
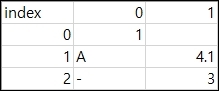
mode 인수의 사용
mode 인수는 기본값이 w로 기존 데이터에 새 데이터를 덮어씌웁니다. mode='a'인 경우 기존 데이터 아래에 새 데이터를 추가해서 입력합니다.
df.to_csv(path_or_buf=address+'test9.csv', mode='w') #기존 데이터 csv파일생성
df2 = pd.DataFrame(data=[[7,8],[9,10]],index=[3,4]) # 추가 입력할 새 데이터 객체 생성
df2.to_csv(path_or_buf=address+'test9.csv', mode='a') # mode=a로 기존데이터 아래에 추가함
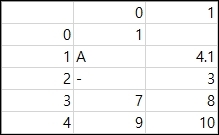
결과는 아래와 같습니다. 기존 데이터 아래에 새 데이터가 추가된것을 확인할 수 있습니다.
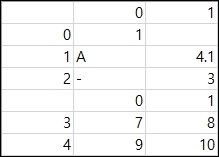
이렇게 단순히 추가하는경우 열 이름이 새로 추가되기 때문에, 보기에 깔끔하지 않습니다. 이경우 header=False하여 새로 추가하는 데이터의 열 이름을 삭제해서 깔끔하게 합치는것이 가능합니다.
df.to_csv(path_or_buf=address+'test10.csv', mode='w')
df2.to_csv(path_or_buf=address+'test10.csv', mode='a',header=False)
결과는 아래와 같습니다. header=False로 열 이름이 삭제되어 깔끔하게 합쳐진것을 확인할 수 있습니다.
quoting / quotechar 인수의 사용
quoting 룰을 지정하고 quotechar 으로 인용구를 표현할 문자를 지정하여 인용구 설정이 적용된 csv파일의 출력이 가능합니다.
quoting에 가능한 값은 {0 : MINIMAL 문자와 특수문자 / 1 : ALL 모든필드 / 2 : NONNUMERIC 숫자가 아닌것 / 3 : NONE 안함}이며, 숫자를 입력하여 지정합니다.
df.to_csv(path_or_buf=address+'test11.csv',quoting=2) # 숫자가 아닌 경우 인용구 처리
결과는 아래와 같습니다. 숫자가 아닌경우에 대해서 인용구 (" ")처리가 된 것을 확인할 수 있습니다.

quotechar='-' 하여 인용구처리를 쌍따옴표("") 가 아닌 하이픈(-) 으로 지정해보겠습니다.
df.to_csv(path_or_buf=address+'test12.csv',quoting=2,quotechar="-")
결과는 아래와 같습니다. 기본 인용구 처리기호인 쌍따옴표가 아닌 하이픈으로 인용구 처리가 된 것을 확인할 수 있습니다.

doublequoto / escapechar인수의 사용
df의 3행1열의 값은 하이픈(-)으로 만약 quotechar을 하이픈(-)으로 한다면 인용구 문자를 인용구 처리하는 경우가 생깁니다.
이 경우 doublequoto=True 인 경우 그냥 무시하고 인용구 처리를 하게 되며, doublequoto=False인 경우 quotechar으로 지정되어 중복되는 값을 다른 문자로 대체합니다.
이 경우 escapechar인수를 통해 대체할 문자의 지정이 가능합니다
df.to_csv(path_or_buf=address+'test13.csv',
quoting=2,quotechar="-",doublequote=False,escapechar="$")
결과는 아래와 같습니다. 변경된 인용구 처리 기호인 하이픈(-) 에 대해서 이미 값이 하이픈(-)인 3행2열의 값이 escapechar="$"의 $로 변경된 것을 확인할 수 있습니다.

'파이썬완전정복-Pandas DataFrame > 19. 형식 변환' 카테고리의 다른 글
| Pandas DataFrame 19-07 html으로 변환(to_html) (0) | 2022.03.14 |
|---|---|
| Pandas DataFrame 19-05 Markdown으로 변환 (to_markdown) (0) | 2022.03.14 |
| Pandas DataFrame 19-04 dict로 변환 (to_dict) (0) | 2022.03.14 |
| Pandas DataFrame 19-03 클립보드에 저장 (to_clipboard) (0) | 2022.03.14 |
| Pandas DataFrame 19-02 excel로 변환 (to_excel) (0) | 2022.03.14 |